
10 Common Code Refactoring Experiences|Elixir

A better coding style for better results
This article comprises of common Elixir coding techniques that you may or may not know.
1— Default Value for absent key in a Map
We usually encounter a situation like we expect a map has certain key and if not we need to send some default value.
Immediately, we will end up using Map.has_key? like in the following way
currency =
if(Map.has_key? price, "currency") do
price["currency"]
else
"USD"
If you see any such lines in your code then it is time to refactor them as
currency = Map.get(price, "currency", "USD")
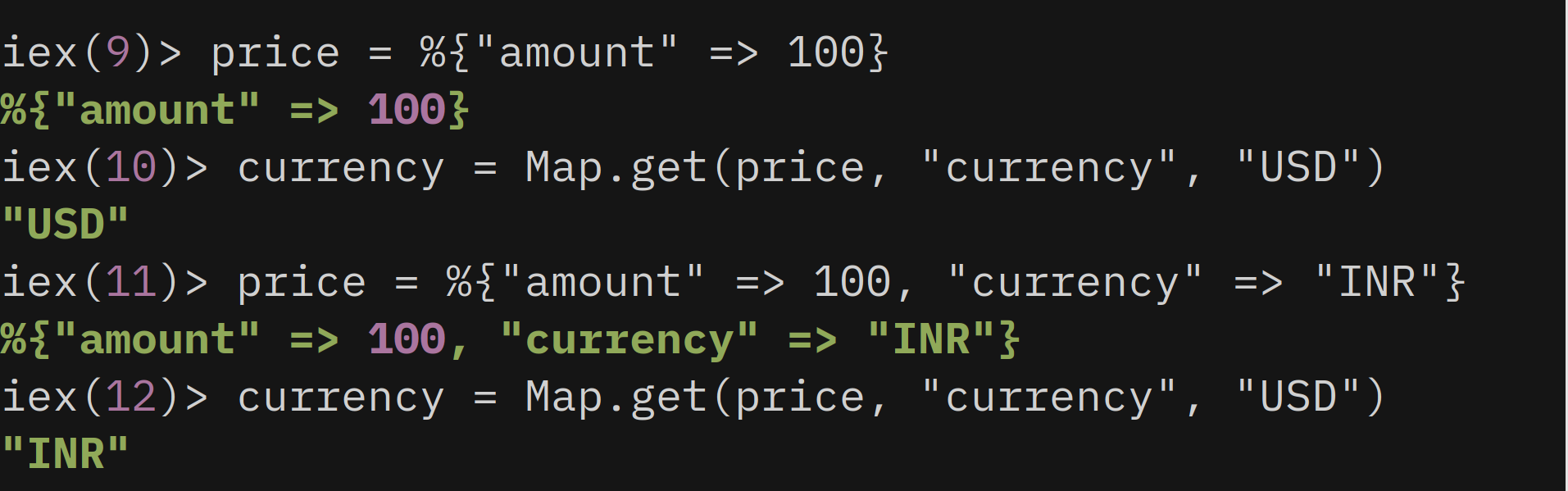
If price has key currency with value nil then it returns nil . It just looks for the absence of a key to return default value.

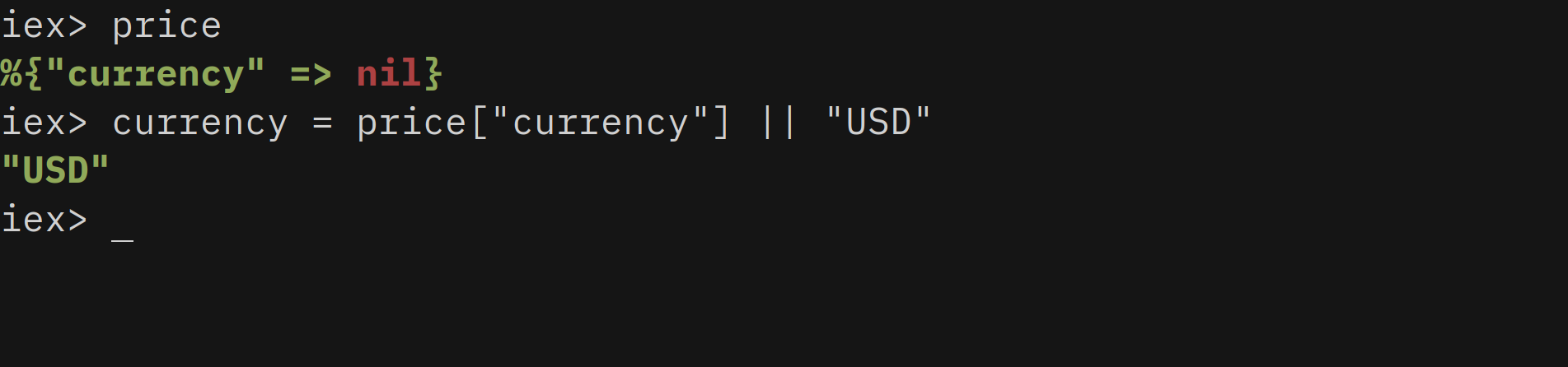
However, you can take this to the next level like
currency = price["currency"] || "USD"

2 — Template Rendering | Phoenix
We always end up rendering different flash messages based on the HTTP response we got to the request we have made.
For example, check the following code
case Booking.update_booking(booking, booking_params) do
{:ok, booking} ->
conn
|> put_flash(:info, "Booking updated successfully")
|> redirect(to: booking_path(conn, :show))
{:error, changeset} ->
conn
|> put_flash(:info, "Error updating Booking")
|> redirect(to: booking_path(conn, :show))
end
The code contains a same line redirect(to: booking_path(conn, :show)) in both matching cases. Any how, we need to redirect to the same template show here.
I have seen similar coding blocks in one of my projects.
We can refactor it by just updating the conn
conn =
case Booking.update_booking(booking, booking_params) do
{:ok, booking} ->
put_flash(conn, :info, "Booking updated successfully")
{:error, changeset} ->
put_flash(conn, :info, "Error updating Booking")
end
redirect(to: booking_path(conn, :show))
3— Defining a subset of a Map
The time when we were ready to burn our hands by writing production level code, we see huge map structures. Especially, developers working in booking style API development. Some times we end up taking few elements and forming a new map like in the following
#Huge Map
pickup = %{
"zip" => "75010",
"town" => "PARIS",
"stopName" => "RECEPTION ",
"pickupId" => 4018,
"longitude" => 2.360982,
"latitude" => 48.868502
.... #a lot of keys
}
It is a pickup information. For some reasons, people asked to me send only latitude and longitude with a key as location. So, we usually end up doing in the following way
#Don’t do
longitude = pickup["longitude"]
latitude = pickup["latitude"]location = %{
"longitude" => longitude,
"latitude" => latitude
}
We can achieve this using Map.take
# Do
location = Map.take pickup, ~w(latitude longitude)
4 — Modifying Keys in a Map
It is very common to the people working B2B companies where they have to update certain keys based on their agent or client requirement.
They receive a response from the supplier and they need to send with a different format of keys.
Example… You will get latitude key and you have to send it as lat.
We do that simply taking out latitude value and inserting the lat key with the latitude value here and deleting the latitude key later.
This involves the following steps…
Taking out the required key and storing in a variable
Inserting new key with the value stored in `step` `1`
Deleting the key to avoid two keys with the same value
and it is not recommended.
#Don’t Do
pickup = %{
"latitude" => 48.868502,
"longitude" => 2.360982,
"pickupId" => 4018,
"stopName" => "RECEPTION",
"town" => "PARIS",
"zip" => "75010"
}
latitude = Map.get(pickup, "latitude") --> step 1
pickup = Map.put(pickup, "lat", latitude) --> step 2
pickup = Map.delete(pickup, "latitude") --> step 3
If the keys grow, then it becomes laborious to update the map. What if you need to update all the keys? It is just a night mare to think. It is uphill.
Suppose, if you want to update all the keys to the following format
latitude -> lat
longitude -> long
pickupId -> pickup_id
stopName -> stop_name
zip -> zipcode
If we go with our above 3 step style we end up with huge LOC. But, we can enumerate the map as in the following way using Map.new/2
#Do
updated_pickup =
Map.new(pickup, fn
{"latitude", lat} -> {"lat", lat}
{"longitude", long} -> {"long", long}
{"pickupId", pickup_id} -> {"pickup_id", pickup_id}
{"stopName", stop_name} -> {"stop_name", stop_name}
{"zip", zip} -> {"zipcode", zip}
anything -> anything
end)
Here, we are taking the advantage of pattern matching inside anonymous function.
5 —Avoid List Concatenation at End- List Appending
🔥 This topic gonna be lengthy, as it needs to well explained with solid examples.
Developers always need to modify things according to the requirement. One of the major operations is adding new things dynamically to the existing list and preserving the order.
However, in Elixir, this gonna be a little tricky. Like we already knew the lists in Elixir are linked_list in structure.
The appending to a list is a familiar operation in any other languages. But in elixir, the data is always immutable never gets changed but referred to some other values.
In a list, each element is bounded with some other next element in the same list. Like so, up to the end of the element. Once if we append an element to the list, each bounding variable had referenced before gets updated. So, to obtain the data immutability, the entire list will be duplicated. As the list grows, this operation gonna be back breaking.
Consider the list [n | [1,2,3,4]] here n is pointing to the first element of the list as List in elixir is a linked_list. So, we no need to duplicate the array [1,2,3,4] as we can directly point to the first element in the list. At this point, we are having only extra n -> [1,2,3,4] in memory.
In the case of [1,2,3,4] ++ [n] we are having [1,2,3,4] and [1,2,3,4,n] in the memory. It duplicates the data to ensure other references aren’t affected.
Adding to the front still allows other references to be unchanged and doesn’t duplicate the list.
However, to see the effect in live consider executing following lines of code
list = Enum.reduce(1..100_000, [], fn(n, acc) -> [n | acc] end)
This code builds up a list 1 item at a time up to 100,000 items. At each step, the item is added to the front of the list.
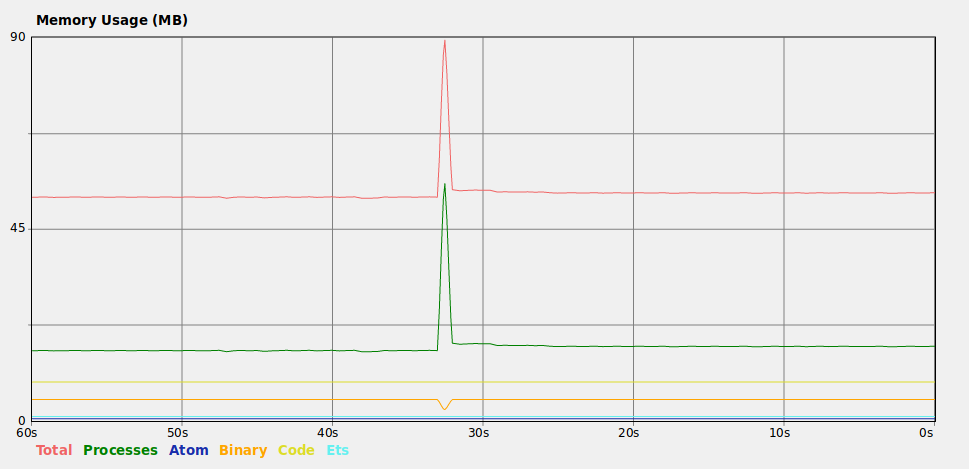
You will notice in the IEx output that the version adding to the front has the list in reverse order. Perhaps you want the list to be [1, 2, 3, 4, ...]. This next line is an adaptation of the first, more efficient one. It efficiently builds up a large list, then re-creates the list 1 time and reverses the order.
list = Enum.reduce(1..100_000, [], fn(n, acc) -> [n | acc] end) |> Enum.reverse()
This next line of code builds up the list by adding to the end. This causes the list to be re-created 100,000 times. As the list grows, it becomes a more expensive operation.
list = Enum.reduce(1..100_000, [], fn(n, acc) -> acc ++ [n] end)
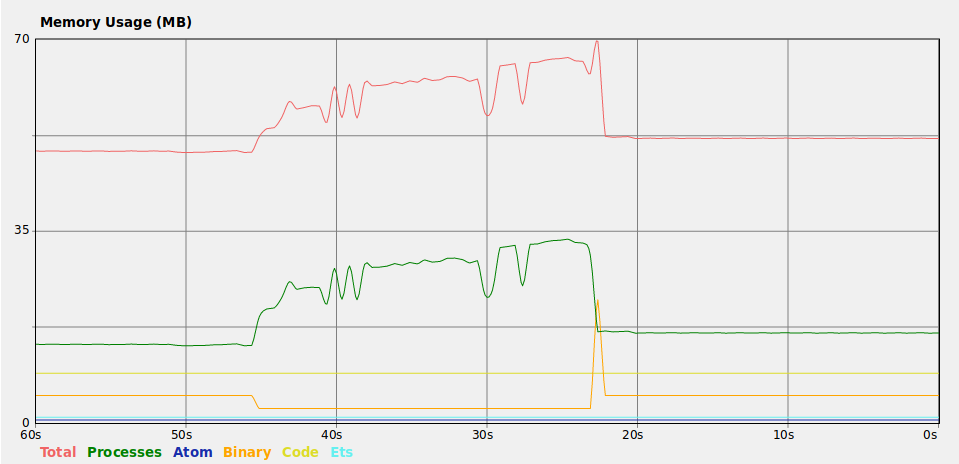
It is pretty clearly to see the RAM climbs and drops and climbs again. Garbage collection is cleaning up the memory that isn’t being referenced.
Feel free to run both in IEx. Even without benchmark times you will see and feel the difference.
🔥 Appending rarely and only a single item is fine, but if you build a list step by step, then you should build it by pretending and reversing at the end.
6 — Results Based on Condition truthiness
Sometimes we expect a value as nil. If it is nil we have to sent some other descent value instead of it. In developers language, a default value has to be sent.
#Don’t
if price == nil do
"$100"
else
price
end
However, people suggested using is_nil function
if is_nil(price) do
"$100"
else
price
end
We can still improvise this as
#Do
price || "$100"
Hurray! We haven’t used if-else here. It is clean and self-explaining. However, don’t go for price or "$100" as or expects its parameters to be boolean values i.e either true or false but not any other elixir term.
Let’s dig more inside for similar things…
Personally experienced a situation of getting boolean as binary and modifying it as an actual boolean value.
I am getting True as binary instead of true the boolean. So, I need to update that accordingly.
#Before Don't do
bool_status =
if status == "True" do
true
else
false
end
If you observe here, we are expecting boolean based on the status. We forgot that == returns boolean itself.
The above lines can be refactored to something like
#Do
bool_status = status == "True"
Here, once again we avoid using if-else block.
7 — Give a Name to the Condition-Self Descriptive
Sometimes, we have to evaluate multiple conditions based on values. One out of my experiences is I need to execute a few lines of code by checking whether the user who logged in is either admin, grn_admin, super_admin, agent, or super_agent.
I saw a code something like
if user == "admin" or
user == "grn_admin" or
user == "super_admin" or
user == "agent" or
user == "super_agent" do
#do some stuff
else
#do some other stuff
end
Though it does the purpose, it looks weird.
It can be refactored into
def valid_user? user do
user in ~w(admin grn_admin super_admin agent super_agent)
end
if valid_user?(user) do
#do some stuff
else
#do some other stuff
end
8 — Nested Data Comprehensions Enum.map Vs For
Requirement to generate list of strings based on
operators = ["supplier", "agent"]
operations = ["search", "recheck", "refetch", "booking"]
modes = ["request", "response"]
Based on that I need to generate a list of log files like
[
"supplier_search_request.log",
"supplier_search_response.log",
"agent_search_request.log",
"agent_search_response.log",
"supplier_recheck_request.log",
"supplier_recheck_response.log",
"agent_recheck_request.log",
"agent_recheck_response.log",
"supplier_refetch_request.log",
"supplier_refetch_response.log",
"agent_refetch_request.log",
"agent_refetch_response.log",
"supplier_booking_request.log",
"supplier_booking_response.log",
"agent_booking_request.log",
"agent_booking_response.log"
]
So, the immediate idea we get is to use Enum module as it has enormous of functions to work with.
Let’s check that…
#Don’t Do
Enum.map(operators, fn operator ->
Enum.map(operations, fn operation ->
Enum.map(modes, fn mode ->
"#{operator}_#{operation}_#{mode}.log"
end)
end)
end) |> List.flatten()
After getting the results, I need to use List.flatten to flatten the nested list.
Now let’s try using for macro.
#Do
for operator <- operators,
operation <- operations,
mode <- modes do
"#{operator}_#{operation}_#{mode}.log"
end
It saves you from heavy typing, clumsy look, and another extra conversion. Now it is pretty clear and easily understandable.
9 — Enumerating a Collection & result as a Map
I always used to use Enum.map/2 followed by Enum.into/2 to achieve this. For example, we are having a list of filenames and we need to preserve their file_descriptors by opening those files. So, I used the key as filename and value as file_descriptor.
#Don’t Do
file_names
|> Enum.map(fn file_name ->
{:ok, file_descriptor} = File.open(file_name, [:append])
{file_name, file_descriptor}
end)
|> Enum.into(%{})
In the above code snippet, we used Enum.map/2 followed by Enum.into/2 . We can achieve this with single function Enum.into/3
#Do
Enum.into(file_names, %{}, fn name->
{:ok, file} = File.open(name, [:append])
{name, file}
end)
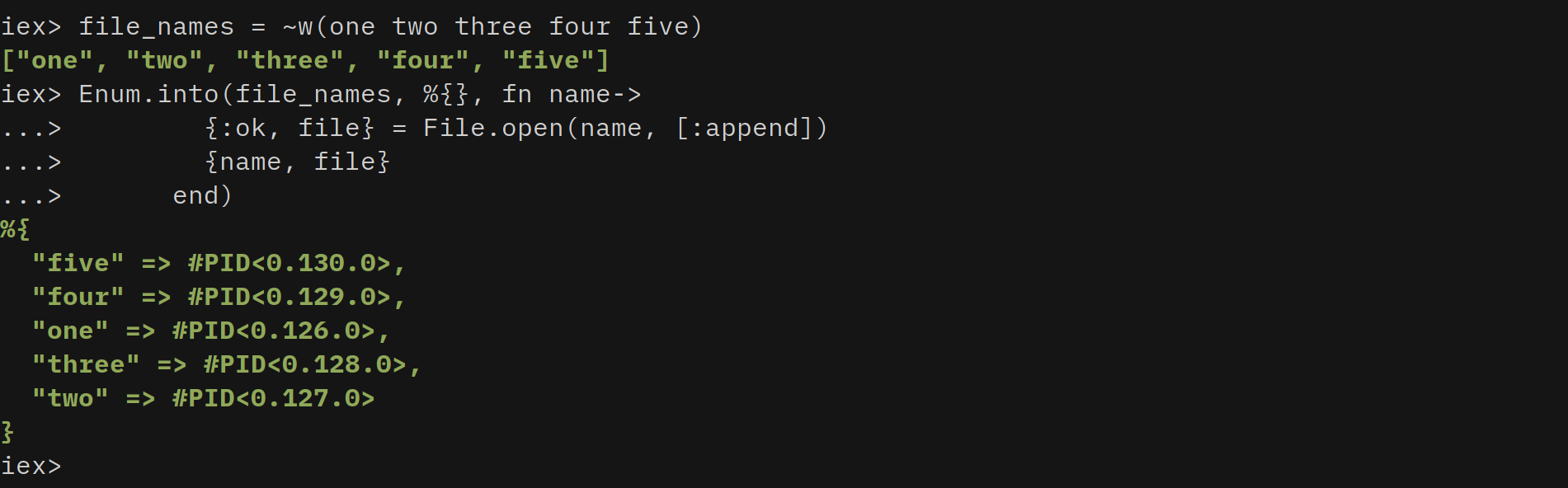
It is also useful when we have a requirement to merge two maps by modifying one of the maps keys.
Enum.into(modify_map, merge_map, fun)
10 — Defining Ecto Schema Fields for validations __schema__
After defining the schema, we used to group the schema fields for validating and updating or for some other purpose like @required_fields [<list of fields>] and so on.
However, if our schema consists of more fields and all are required then to define @required_fields to pass as a parameter to the Ecto validator validate_required(changeset, @required_fields) would be an immense list of fields and it is not recommended to do.
Let’s check what to do and what not to do.
embedded_schema do
field :carrier_time, :string
field :carrier_date, :string
field :carrier_name, :string
field :carrier_number, :string
field :carrier_terminal, :string
field :carrier_type, :string
end
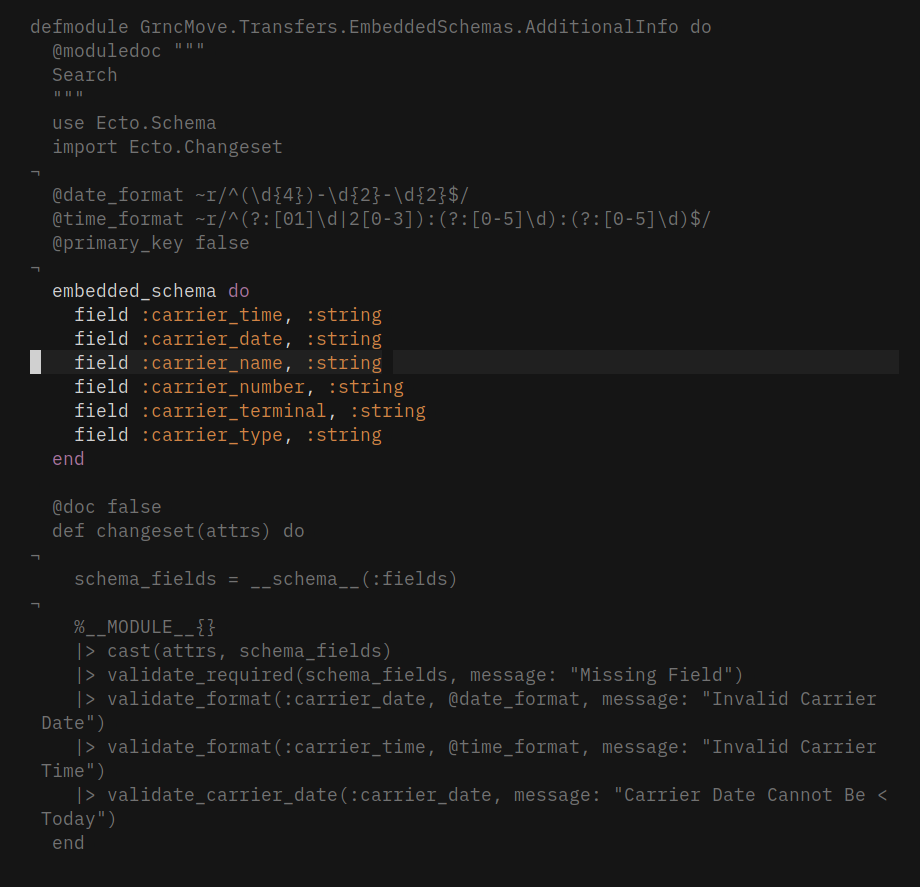
#Don’t Do
@required_fields [:carrier_time, :carrier_date, :carrier_name, :carrier_number, :carrier_terminal, :carrier_type]
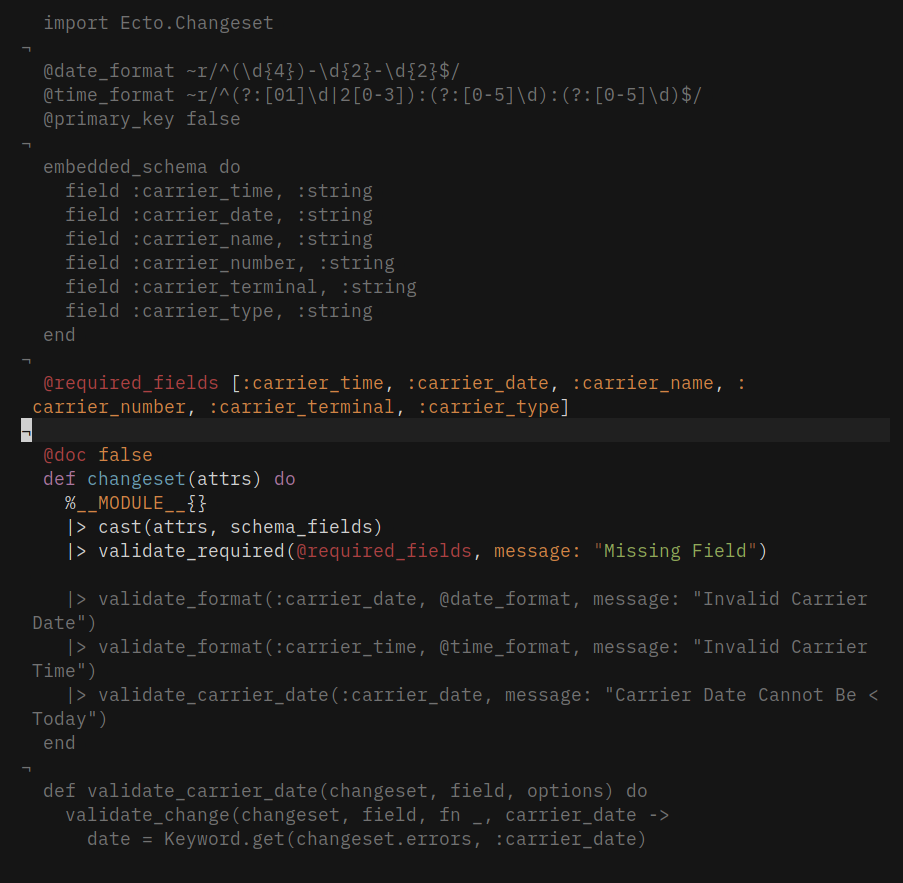
#Do
Like 👆above, you don’t need to redefine the list as we can use __schema__ which does the job
__schema__(:fields) #returns a list of schema fields
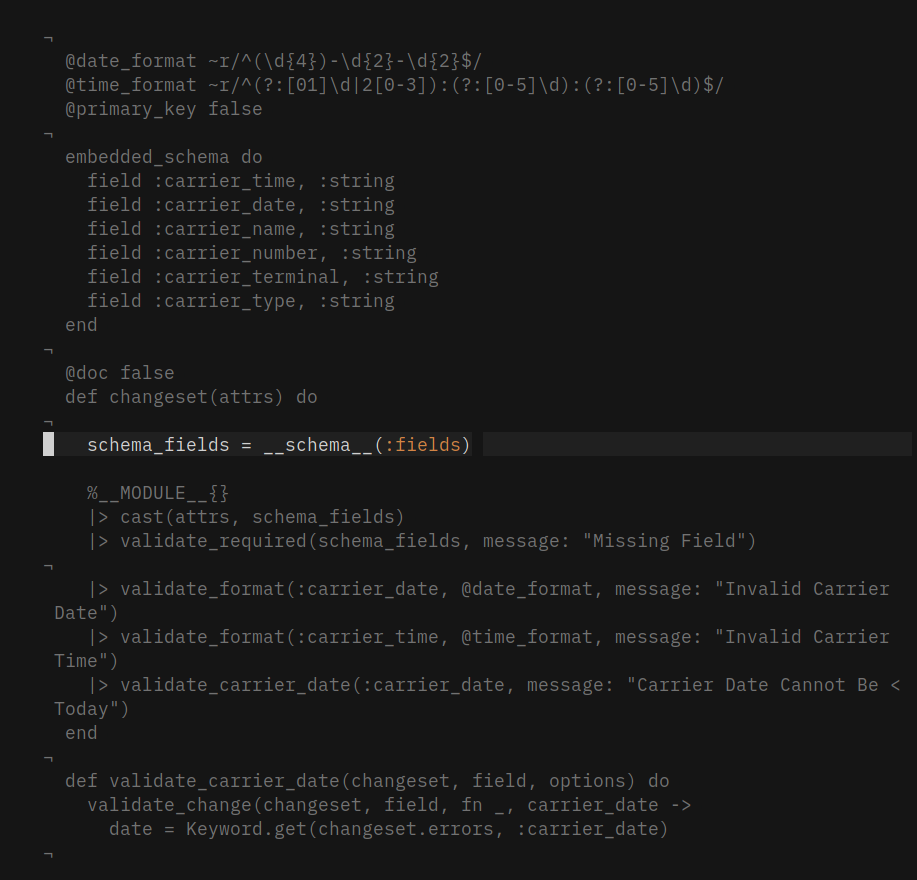
If not all the schema fields are required then subtract the unwanted fields like below
non_required_fields = ~w(carrier_terminal carrier_type)a
__schema__(:fields) -- non_required_fields
It saves our development time and avoids re defining a list, the redundancy code.
Love to hear your thoughts ❤️
The article featured in Plataformatec